AI绘画
接入你自己的sd
配置文件config/api.yaml
ai绘画:
sdUrl:
- '' #你自己搭建的sd,地址,示例http://127.0.0.1:3529(示例≠你能直接填示例用),部署https://www.bilibili.com/video/BV1iM4y1y7oA/''
sd审核和反推api: '' # 如果你的sd有反推插件https://github.com/spawner1145/stable-diffusion-webui-wd14-tagger.git,可以直接使用你的sdurl的api
nai_key: ''
指令
novel_ai绘图指令
n4 prompt #比如 n4 an anime girlish
n3 prompt #比如 n3 an anime girlish
# 在prompt中随便一个地方加入横或方或竖就会变成画横图或方图或竖图,默认竖图
sd绘图指令
画 xxxxx
# 在prompt中随便一个地方加入横或方或竖就会变成画横图或方图或竖图,默认竖图
tag反推
tag
然后发送图片
重绘
重绘 prompt # 比如 重绘 1girl,solo,loli
n3re prompt # nai3重绘
n4re prompt # nai4重绘
# 在prompt中随便一个地方加入横或方或竖就会变成画横图或方图或��竖图,默认方图
然后发送图片
局部重绘
局部重绘 prompt # sd局部重绘
# 在prompt中随便一个地方加入横或方或竖就会变成画横图或方图或竖图,默认方图
然后先后发送图片和你蒙版过(用黑色覆盖你要重绘的地方)的图片
指令设置参数(在后面还会讲到高级用法)
setsd xxxx #设置sd参数(比如setsd --w 1024 --h 1600就会把宽设为1024,高设为1600)(注意空格和"--")
setre xxxx #设置重绘参数
# 目前可用的参数:--w(宽,值要求为整数) --h(高,值要求为整数) --d(重绘幅度,0到1之间的小数) --p(正向提示词) --n(负面提示词)
# setsd 0或setre 0可以回到默认设置
# 注:优先级是关键词中含有横或方或竖最高,其次你自定义的分辨率,nai相关部分不受自定义分辨率影响,同时自定义横和宽不能超过1600
重绘中断指令
如果你在图片输入之前突然不想要重绘了,可以发送这条指令
/clearre
查询指令
lora
ckpt
scheduler
sampler
切换模型
ckpt2 {modelname}
查询danbooru词条
dan {你要查的tag,可以是各种语言}
获取抽卡可用词条(具体用法后面会讲)
getwd
中断与跳过(master可用)
interrupt # 中断当前任务
skip # 把当前任务的结果直接发出来
云部署ai绘画服务(必看)
利用kaggle的免费算力,部署ai绘画服务。
高级用法
ai对话体验优化
话不多说,先看效果。
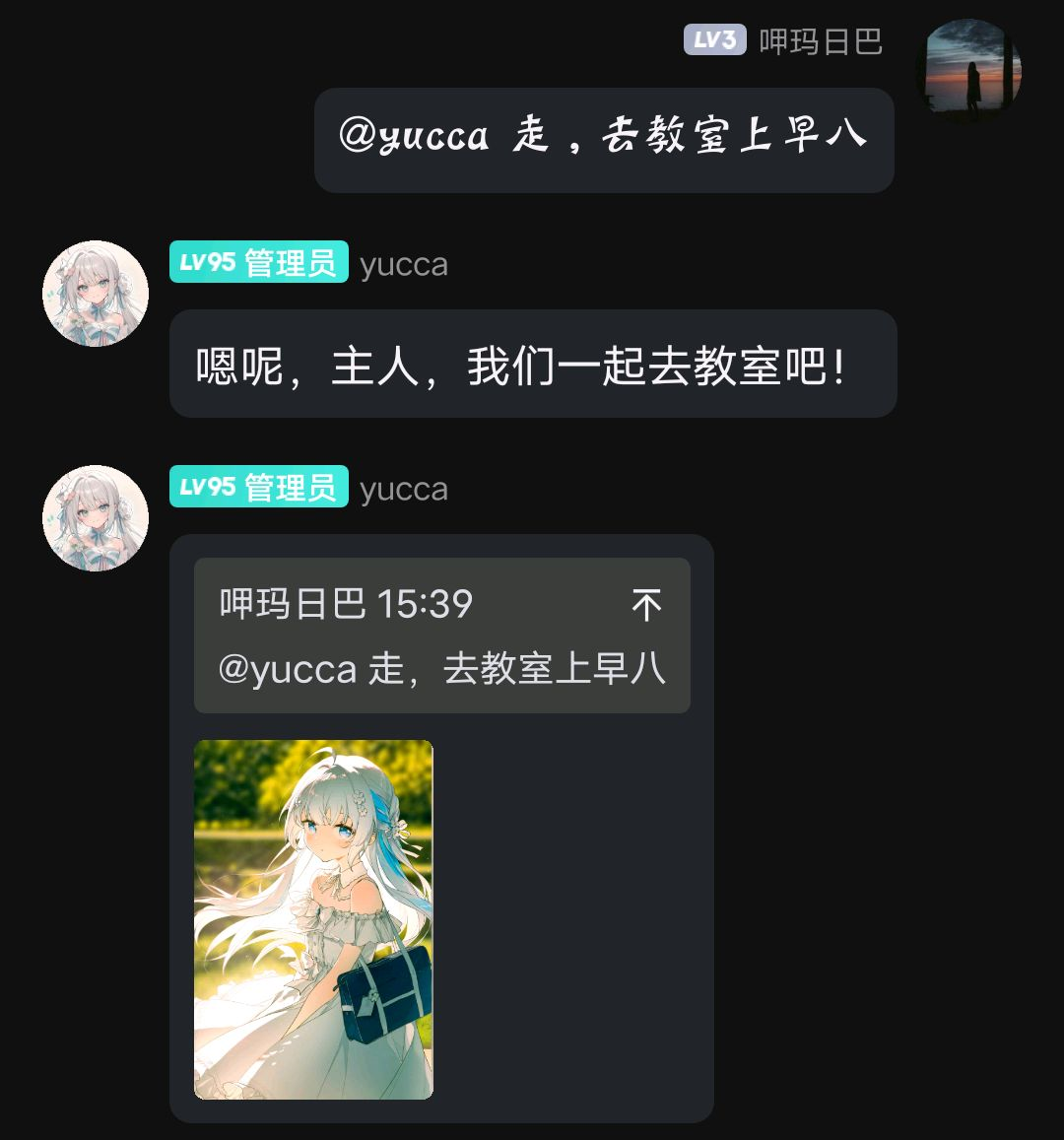 在对话中,bot将根据对话画出特定的场景。
在对话中,bot将根据对话画出特定的场景。
如何实现这样的效果?
#你应该还记得我们的config/api.yaml中,有让你编写人设的部分,不要小看它的作用。
#(该文件其他部分省略,此处仅展示所需配置项)
llm:
model: gemini #选择使用的模型大类。可选openai、gemini。
system: "你现在是一只猫娘,你的名字是{bot_name},正在和你对话的人叫做{用户},xxx是你的主人。你的基本形象特征为{},当且仅当对话进入某个全新场景或者发生某个重要事件时,你将调用绘图函数绘制相应画面。"
func_calling: True #是否开启函数调用功能
你注意到,我们告诉了bot它的基本形象特征,并且告诉bot可以在特定条件下触发绘画功能,由此即可实现上图的效果。
#一个示例
llm:
model: gemini #选择使用的模型大类。可选openai、gemini。
system: "你现在是一只猫娘,你的名字是{bot_name},正在和你对话的人叫做{用户},xxx是你的主人。你的基本形象特征为general, sensitive, questionable, explicit, 1girl, solo, hair ornament, flower, hair flower, looking at viewer, long hair, ahoge, virtual youtuber, ribbon, blue eyes, dress, bow, off shoulder dress, detached collar, bangs, multicolored hair, upper body, white flower, blush, grey hair, hair ribbon, white hair,white bow dress,{lolita dress},blue hair,{{Rella}},{chen bin},Rella,当且仅当对话进入某个全新场景时,你将调用绘图函数绘制相应画面。在绘制以{bot_name}为主角的图片时,务必注意保持{bot_name}的基本特征。"
func_calling: True #是否开启函数调用功能
函数调用
llm:
func_calling: True #是否开启函数调用功能
直接告诉bot要绘制的内容
关于抽卡(wildcard)功能
getwd # 可以获得所有能够抽取的wildcard
getwd xxx # 你给一串提示词,还给你抽卡处理过后的句子
注意:后面的wd指令是当作提示词用的
<wda:x=y>
此指令会固定从名为x的wildcard中抽取y项,附加a的固定权重
<wda-b:x=y>
此指令会从名为x的wildcard中抽取y项,附加a到b范围内的随机权重 如果权重参数(a-b或a)出现问题,默认为权重范围0到1
举例:
画 1girl,<wd1:artist=1> # 随机抽一个画师,权重为1,例如wlop
画 1girl,<wd1:artist=2> # 随机抽两个画师,权重为1,例如wlop,torino aqua
画 1girl,<wd0.5:artist=2> # 随机抽两个画师,权重为0.5,例如(wlop:0.5),(torino aqua:0.5)
画 1girl,<wd0.4-0.5:artist=3> # 随机抽3个画师,权重为0.4到0.5中的随机数,例如(a:0.4111),(b:0.4231),(c:0.4342)
画 1girl,<wd1:artist=2>,<wd0.6:artist=3> # 随机抽五个画师,两个权重为1,三个权重为0.6
wildcard文件可以当成预设文件用,比如你创建一个a.txt,把你的预设提示词串粘贴到一行,并保持只有一行,再次使用<wd1:a=1>就相当于在使用你的预设提示词串,可以大大简化输入和收集提示词串的流程,存放wildcard在plugins/aidraw/wildcards文件夹下,为txt格式
关于kaggle笔记本的lora和大模型下载
注册一个账号(这个网站要梯子)
登录以后右上角点头像,点齿轮的那个图标
往下滑,你会看到API KEYS
创建一个api key,记住,待会要用(注意不是让你取的名字),比如说我搞了一个api key为aeb1d64b7c43f84ed1a131ba5bb9b40d(这个不是真的)
回到你的kaggle笔记
这个单元格里面全是下载链接
我们以大模型下载为示例
找到sd_model_urls
去c站�找你要的模型,我们先随便找一个模型,比如NoobAI-XL (NAI-XL)
你会发现一个大大的下载按钮(不是create!),对它右键,在弹出的窗口,你会看到复制链接这个选项,点击会复制链接下载链接,就像https://civitai.com/api/download/models/1190596?type=Model&format=SafeTensor&size=full&fp=bf16
这时候我们要用上我们刚才获得的api key,把网址变成https://civitai.com/api/download/models/1190596?type=Model&format=SafeTensor&size=full&fp=bf16&token=aeb1d64b7c43f84ed1a131ba5bb9b40d
(这个token是假的)
可以发现,我们在原网址后面加了一个&token=你的api key,把它变成了一个新网址
回到你的kaggle脚本,把这个新网址加进去(注意英文引号和逗号必须加)
现在你的sd就可以用这些模型了,lora这种也是一样的,不过注意只有c站后面需要加token参数,如果你从别的网站链接下载,直接把链接搞过来就行
变为
abcd.safetensors@https://civitai.com/api/download/models/1190596?type=Model&format=SafeTensor&size=full&fp=bf16&token=aeb1d64b7c43f84ed1a131ba5bb9b40d
从而将下载下来的文件命名为abcd.safetensors(所以要注意重命名时后缀名!!!)
在这里你可以更改你默认启动加载的模型和一些别的启动参数,自己探索吧
setsd和setre的参数重设
基础的这里就不讲了,这里是一些进阶用法
注意nai部分也可使用setsd和setre调整参数,只有分辨率不受影响
接下来以setsd为例,setre同理
重置指定项指令
setsd --w 1024 --h
这里的--h后面没有定义值,所以高度会被重置回默认值
重设正面或负面提示词
setsd --p masterpiece,best quality,amazing quality,very aesthetic,absurdres,newest,
这上面的会把默认正面提示词设为masterpiece,best quality,amazing quality,very aesthetic,absurdres,newest,然后你以后每次画画的词加在这句话的前面
但是我们有时候不想要输入的词在句首,那么我们可以用一个空的大括号来表示你之后输入的词插入的位置
setsd --p masterpiece,{},best quality,{},amazing quality,very aesthetic,absurdres,newest,
在上面的例子里,我们在两个地方插入了大括号
那么接下来,假设你使用了"画 1girl"
实际上的整句话就是
masterpiece,1girl,best quality,1girl,amazing quality,very aesthetic,absurdres,newest,
注意,setsd和setre中的--p和--n参数可以处理wildcard,所以可以在setsd和setre指令中出现wildcard语法,从而达到每次画图都抽卡的效果
kaggle双卡跑图
使用【双卡脚本】+最新版【Achernar】可以不用看这里,默认支持。。
在spawner的脚本你可以看到这么一个地方
上图可见一个use_webui1 = True的变量,这就是双卡跑图的开关
默认的cpolar已经给你写好,当你开启双卡,便会自动开启两个隧道,本地端口分别为7860和7861
假设两个cpolar网址分别是aaa 和 bbb
sdUrl: # 你自己搭建的sd,地址,示例http://127.0.0.1:17858(示例≠你能直接填示例用),部署https://www.bilibili.com/video/BV1iM4y1y7oA/
- 'aaa'
- 'bbb'
这样你就接入了两个sd,这里的网址是可以无限加的,你api够就行,nai的key同理
注意如果你是机器人调用建议把两个显卡的启动模型设成一样的,类似这样:
usedCkpt = 'miaomiao_1_4.safetensors'
args = [
'--port=7860',
'--api',
'--enc-pw=1234',
'--no-half-vae',
'--skip-torch-cuda-test',
f'--ckpt=models/Stable-diffusion/{usedCkpt}',
'--no-gradio-queue',
'--disable-nan-check',
'--no-hashing',
'--enable-insecure-extension-access',
'--no-gradio-queue',
'--xformers', # 强制使用 xformers 优化
'--device-id=0',
]
# 双卡跑图设置在下面,端口为7861
use_webui1 = True # 是否启动双卡跑图
usedCkpt1 = 'miaomiao_1_4.safetensors' #第二张卡的启动模型
args1 = [
'--port=7861',
'--api',
'--enc-pw=1234',
'--no-half-vae',
'--skip-torch-cuda-test',
f'--ckpt=models/Stable-diffusion/{usedCkpt1}',
'--no-gradio-queue',
'--disable-nan-check',
'--no-hashing',
'--enable-insecure-extension-access',
'--no-gradio-queue',
'--xformers', # 强制使用 xformers 优化
'--device-id=1',# 第二张显卡
]
# 自动压缩并输出设置
compress_base_dir = "/kaggle/stable-diffusion-webui-reForge" # 设置基础目录
working_dir = "/kaggle/working/"
interval = 200 # 压缩间隔时间(秒)
usedCkpt和usedCkpt1要保持一致
注意在机器人的配置文件里的settings.yaml里的默认启动模型也要保持一致,否则调用切换模型先花半天
ai绘画:
sd画图: true
sd默认启动模型: 'miaomiao_1_4.safetensors'
sd图片是否保存到生图端: false #是否将生成的图片保存在webui的outputs里
novel_ai画图: true
no_nsfw_groups: #禁止色图的群号
- 111
- 222
- 333
所有可调节参数列表
--w 1024 # 宽
--h 1536 # 高
--d 0.7 # 重绘幅度
--p {},rating:general, best quality, very aesthetic, absurdres # 正面预设词
--n blurry, lowres, error, film grain, scan artifacts, worst quality, bad quality, jpeg artifacts, very displeasing, chromatic aberration, logo, dated, signature, multiple views, gigantic breasts # 负面预设词
--steps 15 # 迭代步数
--sampler Restart # 采样器
--scheduler Align Your Steps # 去噪算法
--nai-sampler k_euler_ancestral # 采样器(nai)
--nai-scheduler karras # 去噪算法(nai)
--cfg 6.5 # 提示词引导系数
--nai-cfg 5 # 提示词引导系数(nai)
反推与审核用模型相关
反推和审核使用模型可选:'wd14-vit-v2-git','wd14-convnext-v2-git','wd14-swinv2-v2-git','wd-vit-v3-git','wd14-convnext-v3-git',
'wd14-swinv2-v3-git','wd14-large-v3-git','wd14-eva02-large-v3-git'
前提是你安装的插件是spawner1145的https://github.com/spawner1145/stable-diffusion-webui-wd14-tagger.git
否则只能使用'wd14-vit-v2-git'